
Introducción a de la Inteligencia Artificial
Una de las grandes aplicaciones de la tecnología, que más revuelo está provocando estos últimos años, es el entrenamiento y despliegue de modelos de Inteligencia Artificial. Estos son herramientas de Aprendizaje Automático, entrenados con datos del mundo real, capaces de predecir o clasificar datos de este.
Una de las grandes aplicaciones de la tecnología, que más revuelo está provocando estos últimos años, es el entrenamiento y despliegue de modelos de Inteligencia Artificial. Estos son herramientas de Aprendizaje Automático, entrenados con datos del mundo real, capaces de predecir o clasificar datos de este.
Estos sistemas tenían dos problemas principales:
Un Sistema Basado en Conocimiento solo era capaz de responder a preguntas relacionadas a un tema. Debido a las limitaciones de la época, y a la copiosa tarea de crear un sistema como estos por parte de un equipo, cada sistema estaba programado con información relacionada a un único tema.
Al estar programadas las respuestas de los sistemas (recordemos que estaban basados en largas estructuras de condicionales), estos no podían ser considerados poseedores de inteligencia, por lo que era, en cierto modo, un error pensar que hacían uso de Inteligencia Artificial.
Estos sistemas fueron, junto con los llamados “Sistemas Difusos”, las herramientas de “Inteligencia Artificial” predominantes de la época. Hoy en día, esto ha cambiado mucho, y una herramienta como tal en los tiempos que corren no sería considerada poseedora de inteligencia.
El término “Inteligencia Artificial” se refiere a la cualidad de poder procesar información, y utilizarla para llegar a una conclusión de forma similar a como procesan información las neuronas biológicas. Es por esto que muchas herramientas que han permitido la evolución de este campo han sido desarrolladas basándonos en estudios previos del cerebro humano. De esta forma, hemos logrado crear sistemas que son capaces de procesar información para darnos una respuesta válida, sin necesidad de estar previamente programada. Hemos creado máquinas que son capaces de aprender y pensar por su propia cuenta, aprendiendo en muchos casos a realizar labores mecánicas (y artísticas) con un nivel de rendimiento comparable al logrado por un humano (en algunos casos, hasta superior).
Estos hitos, que no dejan de ser unos logros muy importantes en el campo de la tecnología, y que han permitido y permitirán un desarrollo aún más veloz del mundo que nos rodea, son para muchos la principal fuente de terror que puedan sentir en relación con este campo. La idea de que las máquinas puedan pensar por su propia cuenta, y aprender de nosotros es una idea que a algunos puede no atraer demasiado, y honestamente, de no ser regulado este proceso de aprendizaje, o inclusive la capacidad de las mismas herramientas de IA, podamos tal vez vernos envueltos en un mundo donde estas máquinas nos han sustituido en muchos de los ámbitos laborales. Además, el temor al mal uso de la IA, como la generación y difusión de contenido falso, es otra preocupación válida.
Es importante encontrar un equilibrio entre fomentar la innovación y proteger a la sociedad de posibles riesgos. La regulación adecuada puede garantizar que la IA se utilice de manera ética y responsable, minimizando el riesgo de reemplazo laboral masivo y evitando la propagación de información engañosa. Por otro lado, es esencial educar a la sociedad sobre los beneficios y los desafíos de la IA para tomar decisiones informadas y participar en el desarrollo de políticas que aborden estas cuestiones de manera efectiva.
Proceso de Entrenamiento de modelos de Inteligencia Artificial
El proceso de entrenamiento de los modelos de IA, de forma superficial, es bastante sencillo. Una vez que se ha diseñado una arquitectura apropiada al problema que deseamos solucionar, se envía información del mundo real a dicho modelo, con el objetivo de que pueda aprender acerca de esta, y ser útil para predecir/clasificar correctamente nuevos datos que no haya visto antes.
Un proceso muy importante en antes del entrenamiento, es la preparación de los datos para llevar a cabo el aprendizaje. Estos tienen que estas normalizados, y mantener una distribución que evite cualquier tipo de sesgo hacia un resultado u otro. En caso contrario, el modelo habrá aprendido correctamente acerca de los datos de entrenamiento, pero al no ser estos fieles a la realidad, tampoco lo será el modelo entrenado.
La imagen que se muestra a continuación representa la estructura de un Perceptron simple:
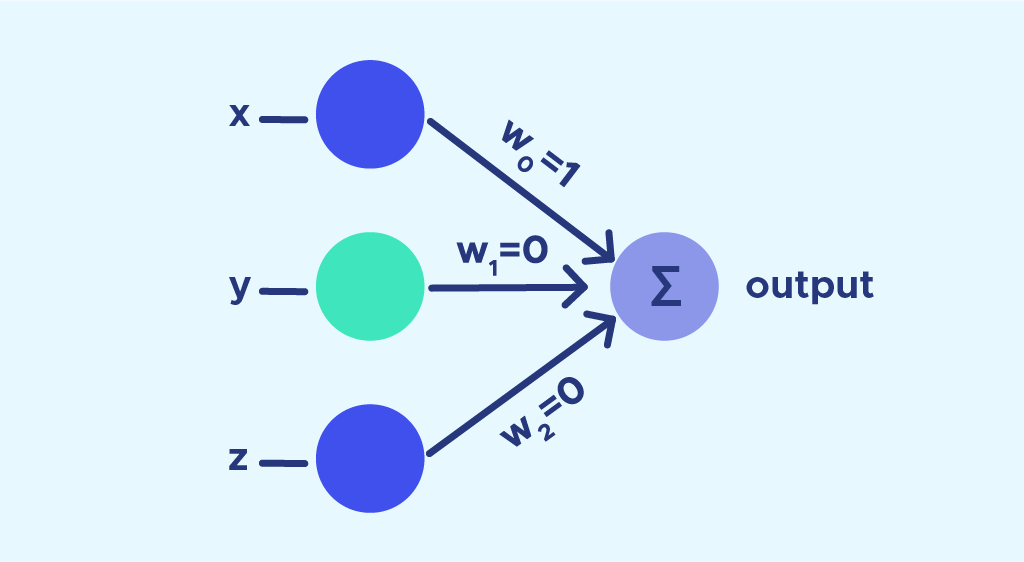
Este modelo de Red Neuronal básica cuenta con únicamente dos capas de neuronas. La primera capa (capa de entrada) es aquella que recibe la información del exterior. Esta capa es la encargada de recibir, por tanto, los datos que le pasamos a la red, y con los que buscamos que sea capaz de buscar patrones ocultos para aprender en base a ellos. La capa de salida es la encargada de devolver valores al mundo real.
Para obtener una salida, todas las neuronas de la primera capa reciben la misma información, a la que le aplican el producto del peso w de la conexión con la siguiente neurona, y le envían dicha información. Al resultado de esta operación, se le aplica algo llamado “función de activación”. Existen varias de ellas, y la elección entre una u otra dependerá del problema que queramos resolver con nuestro modelo.
De esta manera, al recibir datos, generar una salida y compararla con la real, son capaces de modificar sus parámetros para acercarse cada vez más a la salida original. Con esto, la red “aprende” acerca de los datos de entrenamiento que está recibiendo, y tras un correcto entrenamiento, esta será capaz de generalizar el conocimiento con nuevos datos que no haya visto antes.
El modelo de Perceptron mostrado no es útil en tareas que tengan algún componente no lineal, para lo que se requieren arquitecturas más complejas. Sin embargo, lo importante a destacar aquí es el proceso de aprendizaje, que se aplica de igual forma (con algunas variaciones, como algoritmos de backpropagation) a los modelos más complejos.
En última instancia, un modelo entrenado es capaz de activar y desactivar algunas conexiones a su elección, pudiendo adaptarse para ofrecer la respuesta más adecuada a los datos recibidos como entrada.
Problemas éticos en la aplicación de modelos de Inteligencia Artificial
El método de entrenamiento de los modelos de IA se asemeja mucho a como aprendemos los seres humanos. Vemos algo nuevo, lo analizamos, tratamos de comprenderlo y finalmente, logramos aprender de qué trata (en algunos casos, con algo de práctica).
Supongamos que te hacen la siguiente pregunta: “¿Cómo has aprendido a ...?”. La respuesta dependerá de la situación y contexto de la pregunta, pero generalmente podrías responder: “He estado practicando.”, “... leyendo acerca de ello.”, “... he preguntado a gente experta.”, etc. En general, sabríamos dar una respuesta convincente, acerca de porqué hemos aprendido algo, hemos llevado a cabo alguna acción, o hemos dado cierta respuesta a una pregunta dada.
Tratemos ahora de aplicar esta lógica en un modelo de IA. Hemos dicho que estos aprenden realizando operaciones matemáticas con los datos, para poder enviar el resultado de cada neurona a las siguientes capas, hasta finalmente, poder mostrar una salida. Entonces, sabríamos responder a la pregunta: “¿Por qué el modelo muestra que en esta imagen hay un perro y no un gato?”. La respuesta podría citar que el modelo ha aprendido acerca de la información numérica contenida en cada pixel de las imágenes, para luego ir aprendiendo pequeños rasgos comunes, hasta finalmente, la entidad completa de la imagen.
De acuerdo, podríamos dar esta respuesta por válida. Sin embargo, vayamos un paso más hacia delante. Imaginemos un modelo que se aplica a la clasificación de personas, tratando de predecir si una persona puede ser un delincuente o no. Para ello, entregamos al modelo información de dichas personas, entre las que se encuentran imágenes de cada uno. Para sorpresa de muchos, el modelo tiende a clasificar como criminales a personas pertenecientes a cierta étnia, o con una tonalidad más oscura de piel. Si tratamos de responder a la pregunta: “¿Por qué el modelo tiene esta tendencia a clasificar de forma incorrecta a ciertas personas?”, lo único que podríamos hacer sería investigar la información contenida en el modelo, para obtener solamente valores numéricos. Es por esto que un modelo complejo es considerado como una caja negra o “Black Box”. En muchos casos, para los expertos ha resultado difícil saber por qué un modelo ha optado por ofrecer una respuesta u otra (siempre suponiendo que los datos con los que ha sido entrenado el modelo no mostraban ninguna tendencia ni inclinación hacia un resultado u otro).
Este es un caso que ya ha ocurrido, que ha generado polémicas y que supone un debate ético-racial acerca del uso de estas tecnologías para trabajar con información sobre las personas.
¿Supone esto un problema en el uso de Inteligencia Artificial?
Si bien es cierto que podemos comprobar la información almacenada en toda el modelo tras cada etapa del aprendizaje, y que analizar esta información es un proceso complejo para los humanos (más aún cuando los datos de entrenamiento constan de múltiples dimensiones), esto no quiere decir que las redes neuronales sean inherentemente opacas y que no podamos saber el por qué nos muestran un determinado resultado. Más bien, sugiere que necesitamos desarrollar herramientas y métodos para traducir estos valores en explicaciones más accesibles e intuitivas.
Hoy en día, existe un campo en evolución, llamado “Explainable AI”, que se centra en el desarrollo de estas herramientas, que permitan poder comprender e interpretar las predicciones que realizan nuestros modelos de Aprendizaje Automático.
Regularización de la Inteligencia Artificial
En 2023, hemos vivido un completo auge de herramientas de Inteligencia Artificial. Muchas de ellas nacen con el pretexto de poder facilitarnos algunas tareas, pero debido a su gran poder, algunas de estas herramientas han sido utilizadas para generar noticias falsas y difundir bulos por redes sociales. A pesar de que todo el mundo debería investigar acerca de aquello que lee en Internet, muchas personas tienen a creer gran parte del contenido que leen en las plataformas, pensando que parte del contenido generado por IA es real. Este es un hecho que ha ido creciendo conforme pasan los meses, y sumado a otra serie de factores, ha obligado a algunos Gobiernos a tomar medidas de regularización de estas herramientas en los distintos países.
A mediados de 2023, Europa, China y Estados Unidos acordaron una serie de medidas con el objetivo de regular el uso de la Inteligencia Artificial. En el caso de la Unión Europea, esta está trabajando en una regulación (Ley de Inteligencia Artificial) con el fin de abordar el uso ético y transparente de la IA. La regulación tiene como objetivo proteger los derechos de autor y garantizar que las empresas que utilizan IA revelen cualquier material protegido por derechos de autor que hayan utilizado en sus sistemas. Aunque aún no hay consenso, se espera que esta ley entre en vigor en Europa en 2024 para hacer frente a los riesgos asociados con el uso de la IA.
Medidas tomadas por los países para regular la Inteligencia Artificial
Con esto, nos referimos a medidas que hayan decidido implementar los diferentes países, con el objetivo de regular tanto el desarrollo de herramientas que integren Inteligencia Artificial, como el uso desmedido que se le da a las mismas.
Es seguro que las medidas tomadas por las distintas naciones tengan un impacto en todas las personas que hacemos uso de estas herramientas (al final, esto engloba a casi todo el mundo). En un principio, las consecuencias de estas medidas, en relación al público general, podría resumirse de la siguiente manera:
Garantizar que la IA se utilice de manera ética y responsable. Esto podría ayudar a prevenir el uso de la IA para discriminar o perjudicar a las personas.
Proteger los derechos humanos. Las medidas de regulación de la IA podrían ayudar a garantizar que la IA no se utilice para violar los derechos humanos, como la privacidad o la libertad de expresión.
Mejorar la transparencia de la IA. Las medidas de regulación de la IA podrían exigir a los desarrolladores de IA que proporcionen más información sobre cómo funcionan sus sistemas, lo que podría ayudar a los usuarios a tomar decisiones informadas.
A continuación, se mencionan los avances de algunas naciones con respecto a esta decisión:
Unión Europea
La Comisión Europea adoptó la Ley de Inteligencia Artificial en enero de 2023. La ley establece un marco regulatorio para los sistemas de IA de alto riesgo, que incluyen aquellos que se utilizan pIntroducción a de la Inteligencia Artificial
Una de las grandes aplicaciones de la tecnología, que más revuelo está provocando estos últimos años, es el entrenamiento y despliegue de modelos de Inteligencia Artificial. Estos son herramientas de Aprendizaje Automático, entrenados con datos del mundo real, capaces de predecir o clasificar datos de este.
Una de las grandes aplicaciones de la tecnología, que más revuelo está provocando estos últimos años, es el entrenamiento y despliegue de modelos de Inteligencia Artificial. Estos son herramientas de Aprendizaje Automático, entrenados con datos del mundo real, capaces de predecir o clasificar datos de este.
Estos sistemas tenían dos problemas principales:
- Un Sistema Basado en Conocimiento solo era capaz de responder a preguntas relacionadas a un tema. Debido a las limitaciones de la época, y a la copiosa tarea de crear un sistema como estos por parte de un equipo, cada sistema estaba programado con información relacionada a un único tema.
- Al estar programadas las respuestas de los sistemas (recordemos que estaban basados en largas estructuras de condicionales), estos no podían ser considerados poseedores de inteligencia, por lo que era, en cierto modo, un error pensar que hacían uso de Inteligencia Artificial.
Estos sistemas fueron, junto con los llamados “Sistemas Difusos”, las herramientas de “Inteligencia Artificial” predominantes de la época. Hoy en día, esto ha cambiado mucho, y una herramienta como tal en los tiempos que corren no sería considerada poseedora de inteligencia.
El término “Inteligencia Artificial” se refiere a la cualidad de poder procesar información, y utilizarla para llegar a una conclusión de forma similar a como procesan información las neuronas biológicas. Es por esto que muchas herramientas que han permitido la evolución de este campo han sido desarrolladas basándonos en estudios previos del cerebro humano. De esta forma, hemos logrado crear sistemas que son capaces de procesar información para darnos una respuesta válida, sin necesidad de estar previamente programada. Hemos creado máquinas que son capaces de aprender y pensar por su propia cuenta, aprendiendo en muchos casos a realizar labores mecánicas (y artísticas) con un nivel de rendimiento comparable al logrado por un humano (en algunos casos, hasta superior).
Estos hitos, que no dejan de ser unos logros muy importantes en el campo de la tecnología, y que han permitido y permitirán un desarrollo aún más veloz del mundo que nos rodea, son para muchos la principal fuente de terror que puedan sentir en relación con este campo. La idea de que las máquinas puedan pensar por su propia cuenta, y aprender de nosotros es una idea que a algunos puede no atraer demasiado, y honestamente, de no ser regulado este proceso de aprendizaje, o inclusive la capacidad de las mismas herramientas de IA, podamos tal vez vernos envueltos en un mundo donde estas máquinas nos han sustituido en muchos de los ámbitos laborales. Además, el temor al mal uso de la IA, como la generación y difusión de contenido falso, es otra preocupación válida.
Es importante encontrar un equilibrio entre fomentar la innovación y proteger a la sociedad de posibles riesgos. La regulación adecuada puede garantizar que la IA se utilice de manera ética y responsable, minimizando el riesgo de reemplazo laboral masivo y evitando la propagación de información engañosa. Por otro lado, es esencial educar a la sociedad sobre los beneficios y los desafíos de la IA para tomar decisiones informadas y participar en el desarrollo de políticas que aborden estas cuestiones de manera efectiva.
Proceso de Entrenamiento de modelos de Inteligencia Artificial
El proceso de entrenamiento de los modelos de IA, de forma superficial, es bastante sencillo. Una vez que se ha diseñado una arquitectura apropiada al problema que deseamos solucionar, se envía información del mundo real a dicho modelo, con el objetivo de que pueda aprender acerca de esta, y ser útil para predecir/clasificar correctamente nuevos datos que no haya visto antes.
Un proceso muy importante en antes del entrenamiento, es la preparación de los datos para llevar a cabo el aprendizaje. Estos tienen que estas normalizados, y mantener una distribución que evite cualquier tipo de sesgo hacia un resultado u otro. En caso contrario, el modelo habrá aprendido correctamente acerca de los datos de entrenamiento, pero al no ser estos fieles a la realidad, tampoco lo será el modelo entrenado.
La imagen que se muestra a continuación representa la estructura de un Perceptron simple:
Este modelo de Red Neuronal básica cuenta con únicamente dos capas de neuronas. La primera capa (capa de entrada) es aquella que recibe la información del exterior. Esta capa es la encargada de recibir, por tanto, los datos que le pasamos a la red, y con los que buscamos que sea capaz de buscar patrones ocultos para aprender en base a ellos. La capa de salida es la encargada de devolver valores al mundo real.
Para obtener una salida, todas las neuronas de la primera capa reciben la misma información, a la que le aplican el producto del peso w de la conexión con la siguiente neurona, y le envían dicha información. Al resultado de esta operación, se le aplica algo llamado “función de activación”. Existen varias de ellas, y la elección entre una u otra dependerá del problema que queramos resolver con nuestro modelo.
De esta manera, al recibir datos, generar una salida y compararla con la real, son capaces de modificar sus parámetros para acercarse cada vez más a la salida original. Con esto, la red “aprende” acerca de los datos de entrenamiento que está recibiendo, y tras un correcto entrenamiento, esta será capaz de generalizar el conocimiento con nuevos datos que no haya visto antes.
El modelo de Perceptron mostrado no es útil en tareas que tengan algún componente no lineal, para lo que se requieren arquitecturas más complejas. Sin embargo, lo importante a destacar aquí es el proceso de aprendizaje, que se aplica de igual forma (con algunas variaciones, como algoritmos de backpropagation) a los modelos más complejos.
En última instancia, un modelo entrenado es capaz de activar y desactivar algunas conexiones a su elección, pudiendo adaptarse para ofrecer la respuesta más adecuada a los datos recibidos como entrada.
Problemas éticos en la aplicación de modelos de Inteligencia Artificial
El método de entrenamiento de los modelos de IA se asemeja mucho a como aprendemos los seres humanos. Vemos algo nuevo, lo analizamos, tratamos de comprenderlo y finalmente, logramos aprender de qué trata (en algunos casos, con algo de práctica).
Supongamos que te hacen la siguiente pregunta: “¿Cómo has aprendido a ...?”. La respuesta dependerá de la situación y contexto de la pregunta, pero generalmente podrías responder: “He estado practicando.”, “... leyendo acerca de ello.”, “... he preguntado a gente experta.”, etc. En general, sabríamos dar una respuesta convincente, acerca de porqué hemos aprendido algo, hemos llevado a cabo alguna acción, o hemos dado cierta respuesta a una pregunta dada.
Tratemos ahora de aplicar esta lógica en un modelo de IA. Hemos dicho que estos aprenden realizando operaciones matemáticas con los datos, para poder enviar el resultado de cada neurona a las siguientes capas, hasta finalmente, poder mostrar una salida. Entonces, sabríamos responder a la pregunta: “¿Por qué el modelo muestra que en esta imagen hay un perro y no un gato?”. La respuesta podría citar que el modelo ha aprendido acerca de la información numérica contenida en cada pixel de las imágenes, para luego ir aprendiendo pequeños rasgos comunes, hasta finalmente, la entidad completa de la imagen.
De acuerdo, podríamos dar esta respuesta por válida. Sin embargo, vayamos un paso más hacia delante. Imaginemos un modelo que se aplica a la clasificación de personas, tratando de predecir si una persona puede ser un delincuente o no. Para ello, entregamos al modelo información de dichas personas, entre las que se encuentran imágenes de cada uno. Para sorpresa de muchos, el modelo tiende a clasificar como criminales a personas pertenecientes a cierta étnia, o con una tonalidad más oscura de piel. Si tratamos de responder a la pregunta: “¿Por qué el modelo tiene esta tendencia a clasificar de forma incorrecta a ciertas personas?”, lo único que podríamos hacer sería investigar la información contenida en el modelo, para obtener solamente valores numéricos. Es por esto que un modelo complejo es considerado como una caja negra o “Black Box”. En muchos casos, para los expertos ha resultado difícil saber por qué un modelo ha optado por ofrecer una respuesta u otra (siempre suponiendo que los datos con los que ha sido entrenado el modelo no mostraban ninguna tendencia ni inclinación hacia un resultado u otro).
Este es un caso que ya ha ocurrido, que ha generado polémicas y que supone un debate ético-racial acerca del uso de estas tecnologías para trabajar con información sobre las personas.
¿Supone esto un problema en el uso de Inteligencia Artificial?
Si bien es cierto que podemos comprobar la información almacenada en toda el modelo tras cada etapa del aprendizaje, y que analizar esta información es un proceso complejo para los humanos (más aún cuando los datos de entrenamiento constan de múltiples dimensiones), esto no quiere decir que las redes neuronales sean inherentemente opacas y que no podamos saber el por qué nos muestran un determinado resultado. Más bien, sugiere que necesitamos desarrollar herramientas y métodos para traducir estos valores en explicaciones más accesibles e intuitivas.
Hoy en día, existe un campo en evolución, llamado “Explainable AI”, que se centra en el desarrollo de estas herramientas, que permitan poder comprender e interpretar las predicciones que realizan nuestros modelos de Aprendizaje Automático.
Regularización de la Inteligencia Artificial
En 2023, hemos vivido un completo auge de herramientas de Inteligencia Artificial. Muchas de ellas nacen con el pretexto de poder facilitarnos algunas tareas, pero debido a su gran poder, algunas de estas herramientas han sido utilizadas para generar noticias falsas y difundir bulos por redes sociales. A pesar de que todo el mundo debería investigar acerca de aquello que lee en Internet, muchas personas tienen a creer gran parte del contenido que leen en las plataformas, pensando que parte del contenido generado por IA es real. Este es un hecho que ha ido creciendo conforme pasan los meses, y sumado a otra serie de factores, ha obligado a algunos Gobiernos a tomar medidas de regularización de estas herramientas en los distintos países.
A mediados de 2023, Europa, China y Estados Unidos acordaron una serie de medidas con el objetivo de regular el uso de la Inteligencia Artificial. En el caso de la Unión Europea, esta está trabajando en una regulación (Ley de Inteligencia Artificial) con el fin de abordar el uso ético y transparente de la IA. La regulación tiene como objetivo proteger los derechos de autor y garantizar que las empresas que utilizan IA revelen cualquier material protegido por derechos de autor que hayan utilizado en sus sistemas. Aunque aún no hay consenso, se espera que esta ley entre en vigor en Europa en 2024 para hacer frente a los riesgos asociados con el uso de la IA.
Medidas tomadas por los países para regular la Inteligencia Artificial
Con esto, nos referimos a medidas que hayan decidido implementar los diferentes países, con el objetivo de regular tanto el desarrollo de herramientas que integren Inteligencia Artificial, como el uso desmedido que se le da a las mismas.
Es seguro que las medidas tomadas por las distintas naciones tengan un impacto en todas las personas que hacemos uso de estas herramientas (al final, esto engloba a casi todo el mundo). En un principio, las consecuencias de estas medidas, en relación al público general, podría resumirse de la siguiente manera:
- Garantizar que la IA se utilice de manera ética y responsable. Esto podría ayudar a prevenir el uso de la IA para discriminar o perjudicar a las personas.
- Proteger los derechos humanos. Las medidas de regulación de la IA podrían ayudar a garantizar que la IA no se utilice para violar los derechos humanos, como la privacidad o la libertad de expresión.
- Mejorar la transparencia de la IA. Las medidas de regulación de la IA podrían exigir a los desarrolladores de IA que proporcionen más información sobre cómo funcionan sus sistemas, lo que podría ayudar a los usuarios a tomar decisiones informadas.
A continuación, se mencionan los avances de algunas naciones con respecto a esta decisión:
Unión Europea
La Comisión Europea adoptó la Ley de Inteligencia Artificial en enero de 2023. La ley establece un marco regulatorio para los sistemas de IA de alto riesgo, que incluyen aquellos que se utilizan para:
- Tomar decisiones automatizadas que tengan un impacto significativo en las personas.
- Reconocer o identificar a personas.
- Utilizar datos personales sensibles.
Por otra parte, la ley prohíbe los sistemas de IA que violen los derechos humanos o causen daños. También exige a los proveedores de sistemas de IA de alto riesgo que cumplan con una serie de requisitos, como la transparencia, la trazabilidad y la seguridad.
El 14 de junio de 2023, los eurodiputados adoptaron su posición negociadora sobre la ley de IA. A partir de entonces, comenzaron las conversaciones sobre la forma final de la ley en el Consejo Europeo, junto a los países de la UE.
Se prevé que puedan alcanzar un acuerdo a finales de este año.
Estados Unidos
El gobierno de Estados Unidos también está desarrollando un marco regulatorio para la IA.
En 2023, el presidente de Estados Unidos, Joe Biden, firmó una orden ejecutiva que instruye a la Oficina de Ciencia y Tecnología de la Casa Blanca a desarrollar un marco regulatorio que sea "inteligente, responsable y equitativo".
La orden ejecutiva destaca la necesidad de garantizar que la IA se desarrolle y utilice de manera ética y responsable, y que no se utilice para discriminar o perjudicar a las personas.
China
China también está trabajando en un marco regulatorio para la IA que puedan aplicar en la nación. En 2022, el gobierno chino publicó un documento en el que establece una serie de principios para el desarrollo y uso de la IA.
En 2023, se han anunciado una serie de medidas que se aplican a los servicios disponibles para el público en general en China. Con estas nuevas medidas, el Estado de la nación "fomenta el uso innovador de la IA generativa en todas las industrias y campos" y apoya el desarrollo de chips, software, herramientas, potencia de cálculo y fuentes de datos "seguros y fiables", según el documento que anuncia las normas.
China también insta a las plataformas a "participar en la formulación de normas y estándares internacionales" relacionados con la IA generativa.
No obstante, entre las principales disposiciones figura el requisito de que los proveedores de servicios de IA generativa realicen revisiones de seguridad y registren sus algoritmos ante el gobierno si sus servicios pueden influir en la opinión pública o pueden "movilizar" al público.
¿Y tú, qué opinas al respecto?
ara:- Tomar decisiones automatizadas que tengan un impacto significativo en las personas.
- Reconocer o identificar a personas.
- Utilizar datos personales sensibles.
Por otra parte, la ley prohíbe los sistemas de IA que violen los derechos humanos o causen daños. También exige a los proveedores de sistemas de IA de alto riesgo que cumplan con una serie de requisitos, como la transparencia, la trazabilidad y la seguridad.
El 14 de junio de 2023, los eurodiputados adoptaron su posición negociadora sobre la ley de IA. A partir de entonces, comenzaron las conversaciones sobre la forma final de la ley en el Consejo Europeo, junto a los países de la UE.
Se prevé que puedan alcanzar un acuerdo a finales de este año.
Estados Unidos
El gobierno de Estados Unidos también está desarrollando un marco regulatorio para la IA.
En 2023, el presidente de Estados Unidos, Joe Biden, firmó una orden ejecutiva que instruye a la Oficina de Ciencia y Tecnología de la Casa Blanca a desarrollar un marco regulatorio que sea "inteligente, responsable y equitativo".
La orden ejecutiva destaca la necesidad de garantizar que la IA se desarrolle y utilice de manera ética y responsable, y que no se utilice para discriminar o perjudicar a las personas.
China
China también está trabajando en un marco regulatorio para la IA que puedan aplicar en la nación. En 2022, el gobierno chino publicó un documento en el que establece una serie de principios para el desarrollo y uso de la IA.
En 2023, se han anunciado una serie de medidas que se aplican a los servicios disponibles para el público en general en China. Con estas nuevas medidas, el Estado de la nación "fomenta el uso innovador de la IA generativa en todas las industrias y campos" y apoya el desarrollo de chips, software, herramientas, potencia de cálculo y fuentes de datos "seguros y fiables", según el documento que anuncia las normas.
China también insta a las plataformas a "participar en la formulación de normas y estándares internacionales" relacionados con la IA generativa.
No obstante, entre las principales disposiciones figura el requisito de que los proveedores de servicios de IA generativa realicen revisiones de seguridad y registren sus algoritmos ante el gobierno si sus servicios pueden influir en la opinión pública o pueden "movilizar" al público.
¿Y tú, qué opinas al respecto?
